科技生活| Meta新開源AI語音模型 可識別4000多口頭語言

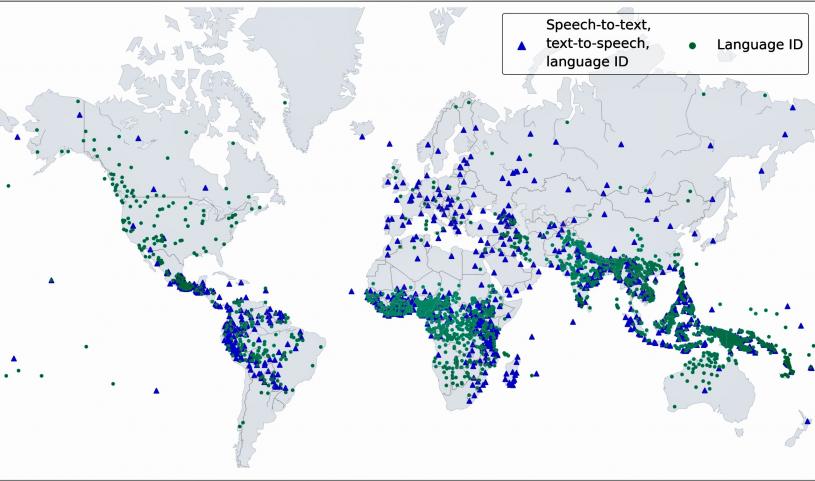
Meta創造了一個令人耳目一新的人工智能語言模型,不是「照抄」ChatGPT。這個大規模多語言語音(MMS)項目可以識別4000多種口語,並產生1100多種語言的語音(文本到語音)。與其他大多數公開宣布的人工智能項目一樣,Meta將MMS開源,以幫助保護語言的多樣性,並鼓勵研究人員在其基礎上進行研究。
該公司寫道:「我們公開分享我們的模型和代碼,以便研究界的其他人能夠在我們的工作基礎上有所發展。通過這項工作,我們希望為保護世界上不可思議的語言多樣性做出一點貢獻。」
語音識別和文本轉語音模型,通常需要對數千小時的音頻進行訓練,並伴隨著轉錄標籤。(標籤是機器學習的關鍵,允許算法正確分類和「理解」數據)。但是對於那些沒有在工業化國家廣泛使用的語言,其中許多語言在未來幾十年內有消失的危機,正如Meta所說,「它們的數據根本不存在」。
Meta使用了一種非常規的方法來收集音頻數據:挖掘翻譯的宗教文本的音頻紀錄。「我們轉向宗教文本,如《聖經》,這些文本已被翻譯成許多不同的語言,其翻譯已被廣泛研究,用於基於文本的語言翻譯研究。這些譯本有公開可用的人們用不同語言閱讀這些文本的錄音。」結合聖經和類似文本的無標籤錄音,Meta的研究人員將該模型的可用語言增加到4000多種。
它聽起來像是一個嚴重偏向基督教世界觀的人工智能模型的配方,但 Meta說情況並非如此。「雖然錄音的內容是宗教性的,但我們的分析表明,這並沒有使模型偏向於產生更多的宗教語言,」Meta寫道,「我們認為這是因為我們使用了連接主義時間分類(CTC)方法,與用於語音識別的大型語言模型(LLM)或序列到序列模型相比,它的約束性要大得多」。此外,儘管大多數宗教錄音是由男性演講者朗讀的,但這也沒有引入男性偏見,在女性和男性的聲音中表現同樣出色。
在訓練了一個對齊模型以使數據更可用之後,Meta使用了wav2vec 2.0,該公司的「自我監督的語音表示學習」模型,可以在未標記的數據上訓練。將非常規的數據源和自我監督的語音模型結合起來,導致了出色的結果。「我們的結果顯示,與現有的模型相比,大規模多語言語音模型表現良好,並且覆蓋了10倍的語言。」具體來說,Meta將MMS與OpenAI的Whisper進行了比較,結果超過了預期。「我們發現,在大規模多語言語音數據上訓練的模型實現了一半的單詞錯誤率,但大規模多語言語音覆蓋的語言是11倍。」
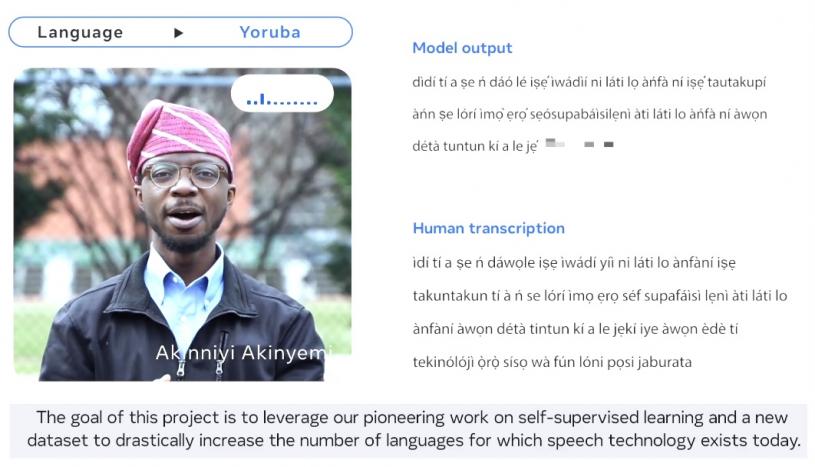
Meta提醒其新模型並不完美。該公司寫道:「例如語音到文本的模型可能會誤寫某些單詞或短語。根據輸出結果,這可能導致冒犯性和/或不準確的語言。我們仍然認為,整個人工智能界的合作對於負責任的人工智能技術的發展至關重要。」
現在,Meta發布MMS的開源研究,它希望它能扭轉技術將世界上的語言縮減到最常被大科技公司支持的100種或更少的趨勢。它看到了這樣一個世界:輔助技術、TTS、甚至VR/AR技術讓每個人都能用自己的母語說話和學習。它說:「我們設想一個技術產生相反效果的世界,鼓勵人們保持他們的語言活力,因為他們可以通過說自己喜歡的語言來獲取信息和使用技術。」
圖片:美聯社
T09
>>>星島網WhatsApp爆料熱線(416)6775679,爆料一經錄用,薄酬致意。
>>>立即瀏覽【生活百答】欄目:新移民抵埗攻略,老華僑也未必知道的事,移民、工作、居住、食玩買、交通、報稅、銀行、福利、生育、教育。









